DynTrace: Tracking Dynamic Object Evidence for 4D Spatio-Temporal Reasoning in MLLMs
ACM MM 2026
Project Page
小红书
arXiv
Abstract
DynTrace is a training-free framework that tracks continuous dynamic object evidence for coherent 4D reasoning. It combines geometry-informed trajectory visualization with a structured Dynamic Trace Graph.
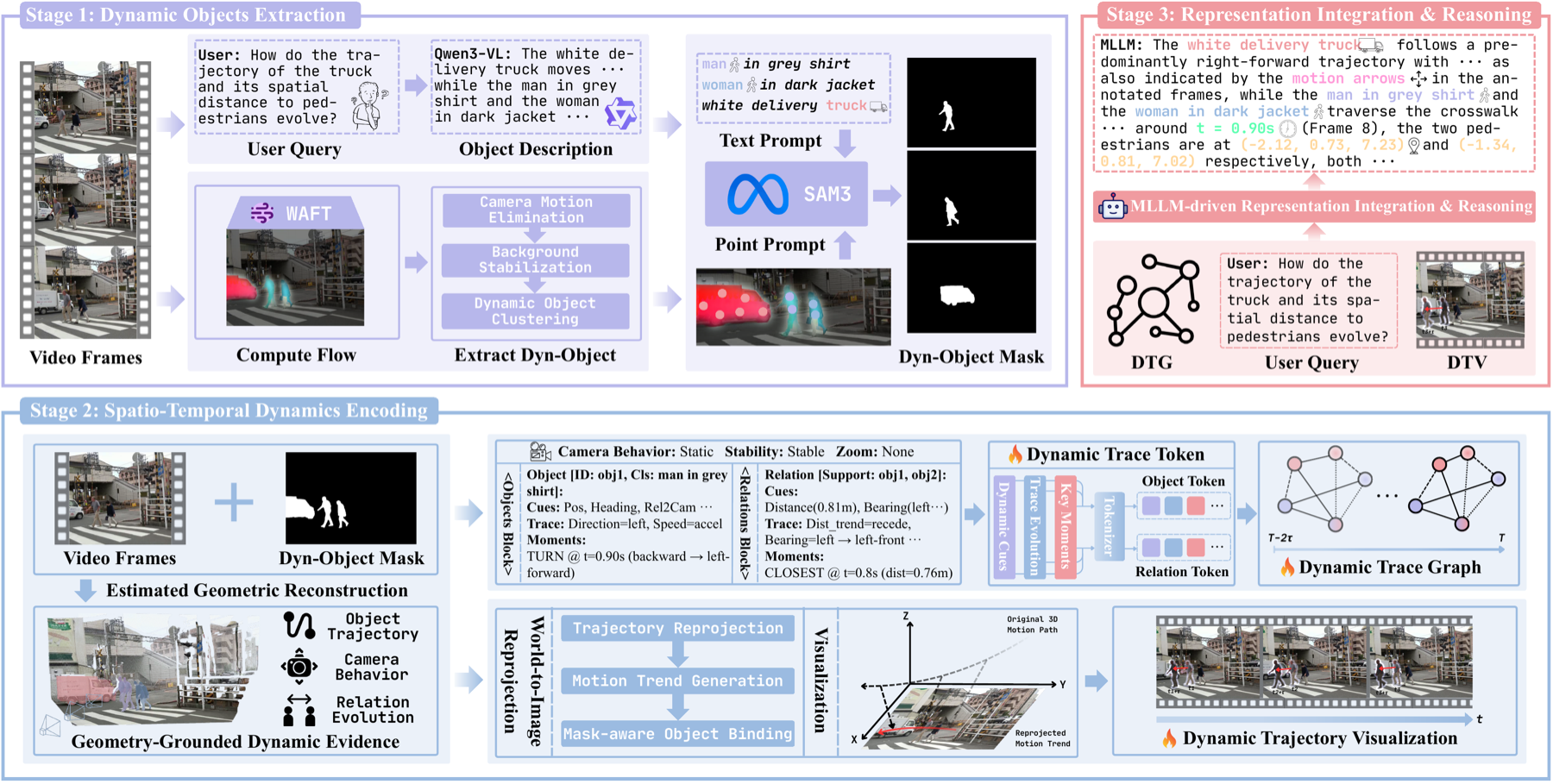
- We introduce DynTrace, a training-free framework that enables MLLMs to continuously track dynamic object evidence for coherent 4D spatio-temporal reasoning. It combines geometry-informed Dynamic Trajectory Visualization with a structured Dynamic Trace Graph to disentangle genuine object dynamics from camera-induced motion and preserve evolving object-level cues across time.