
| CV |
Email |
Github |
|
I am a second-year master student in the School of Informatics at Xiamen University, advised by Prof. Xinghao Ding in the SmartDSP group. I am also collaborating with Dr. Chenxin Li from the AIM group at the Chinese University of Hong Kong.
My current research primarily covers the following topics:
|
|
Project |
Paper |
Abstract
Understanding the dynamic physical world, characterized by its evolving 3D structure, real-world motion, and semantic content with textual descriptions, is crucial for human-agent interaction and enables embodied agents to perceive and act within real environments with human‑like capabilities. However, existing datasets are often derived from limited simulators or utilize traditional Structure-from-Motion for up-to-scale annotation and offer limited descriptive captioning, which restricts the capacity of foundation models to accurately interpret real-world dynamics from monocular videos, commonly sourced from the internet. To bridge these gaps, we introduce DynamicVerse, a physical‑scale, multimodal 4D modeling framework for real-world video. We employ large vision, geometric, and multimodal models to interpret metric-scale static geometry, real-world dynamic motion, instance-level masks, and holistic descriptive captions. By integrating window-based Bundle Adjustment with global optimization, our method converts long real-world video sequences into a comprehensive 4D multimodal format. DynamicVerse delivers a large-scale dataset consists of 100K+ videos with 800K+ annotated masks and 10M+ frames from internet videos. Experimental evaluations on three benchmark tasks---video depth estimation, camera pose estimation, and camera intrinsics estimation---validate that our 4D modeling achieves superior performance in capturing physical-scale measurements with greater global accuracy than existing methods. |
|
|
Project |
Paper |
Abstract |
Code
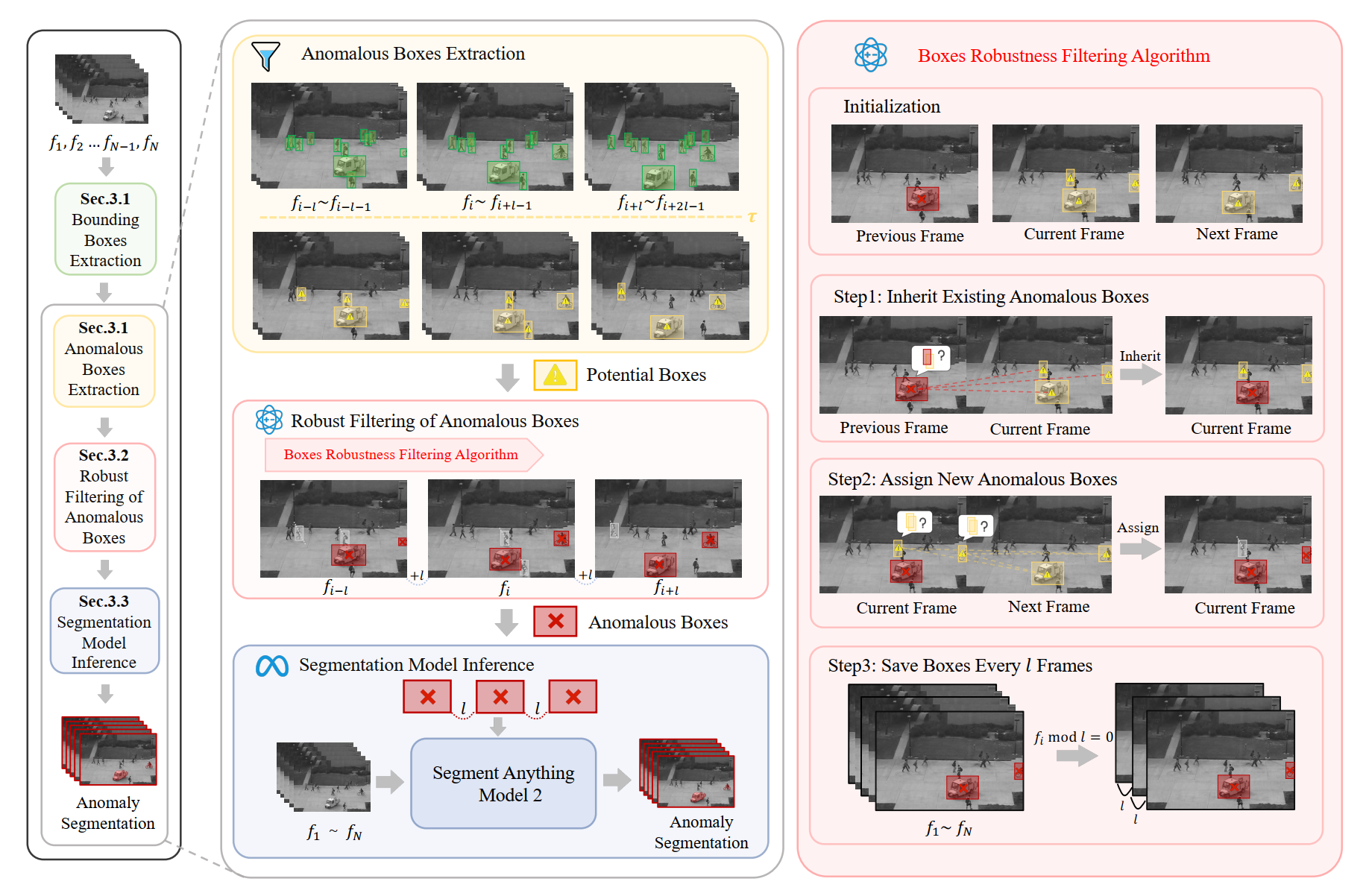
Video anomaly detection (VAD) is crucial in scenarios such as surveillance and autonomous driving, where timely detection of unexpected activities is essential. Albeit existing methods have primarily focused on detecting anomalous objects in videos—either by identifying anomalous frames or objects—they often neglect finer-grained analysis, such as anomalous pixels, which limits their ability to capture a broader range of anomalies. To address this challenge, we propose an innovative VAD framework called Track Any Anomalous Object (TAO), which introduces a Granular Video Anomaly Detection Framework that, for the first time, integrates the detection of multiple fine-grained anomalous objects into a unified framework. Unlike methods that assign anomaly scores to every pixel at each moment, our approach transforms the problem into pixel-level tracking of anomalous objects. By linking anomaly scores to subsequent tasks such as image segmentation and video tracking, our method eliminates the need for threshold selection and achieves more precise anomaly localization, even in long and challenging video sequences. Experiments on extensive datasets demonstrate that TAOachieves state-of-the-art performance, setting a new progress for VAD by providing a practical, granular, and holistic solution. |
|
Project |
Paper |
Abstract |
Code
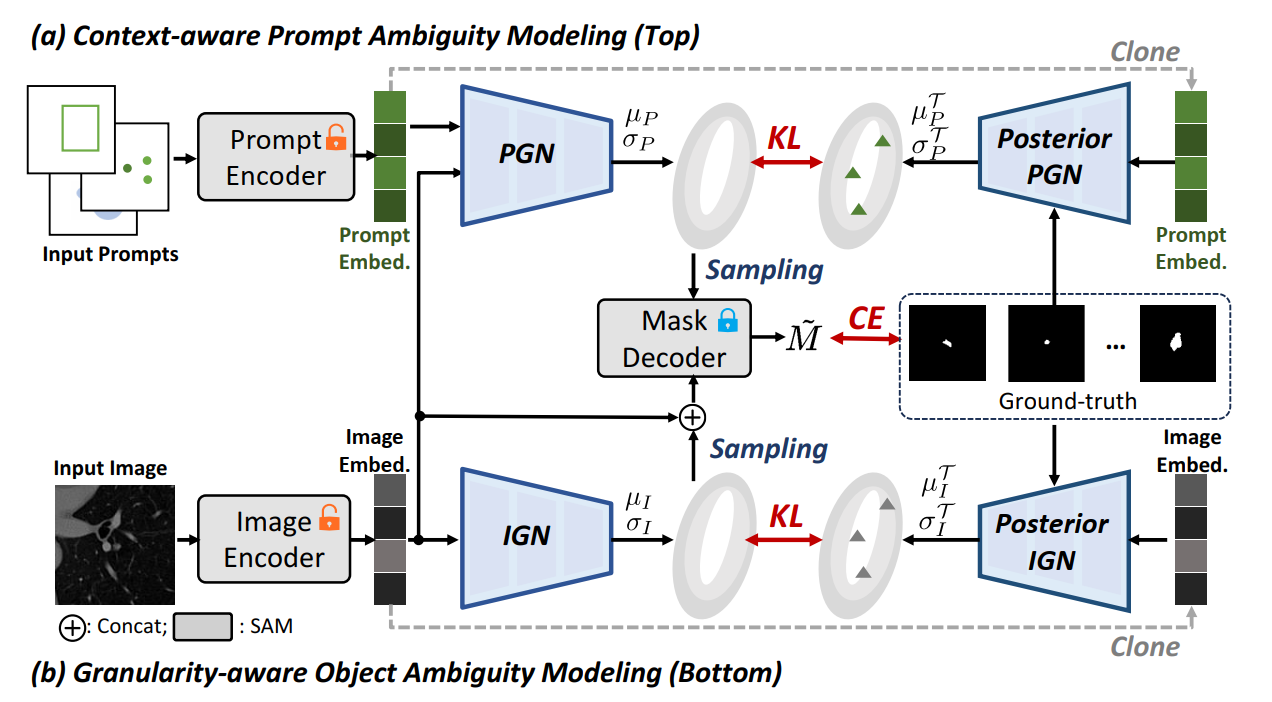
As the vision foundation models like the Segment Anything Model (SAM) demonstrate potent universality, they also present challenges in giving ambiguous and uncertain predictions. Significant variations in the model output and granularity can occur with simply subtle changes in the prompt, contradicting the consensus requirement for the robustness of a model. While some established works have been dedicated to stabilizing and fortifying the prediction of SAM, this paper takes a unique path to explore how this flaw can be inverted into an advantage when modeling inherently ambiguous data distributions. We introduce an optimization framework based on a conditional variational autoencoder, which jointly models the prompt and the granularity of the object with a latent probability distribution. This approach enables the model to adaptively perceive and represent the real ambiguous label distribution, taming SAM to produce a series of diverse, convincing, and reasonable segmentation outputs controllably. Extensive experiments on several practical deployment scenarios involving ambiguity demonstrates the exceptional performance of our framework. |
|
Project |
Paper |
Abstract |
Code
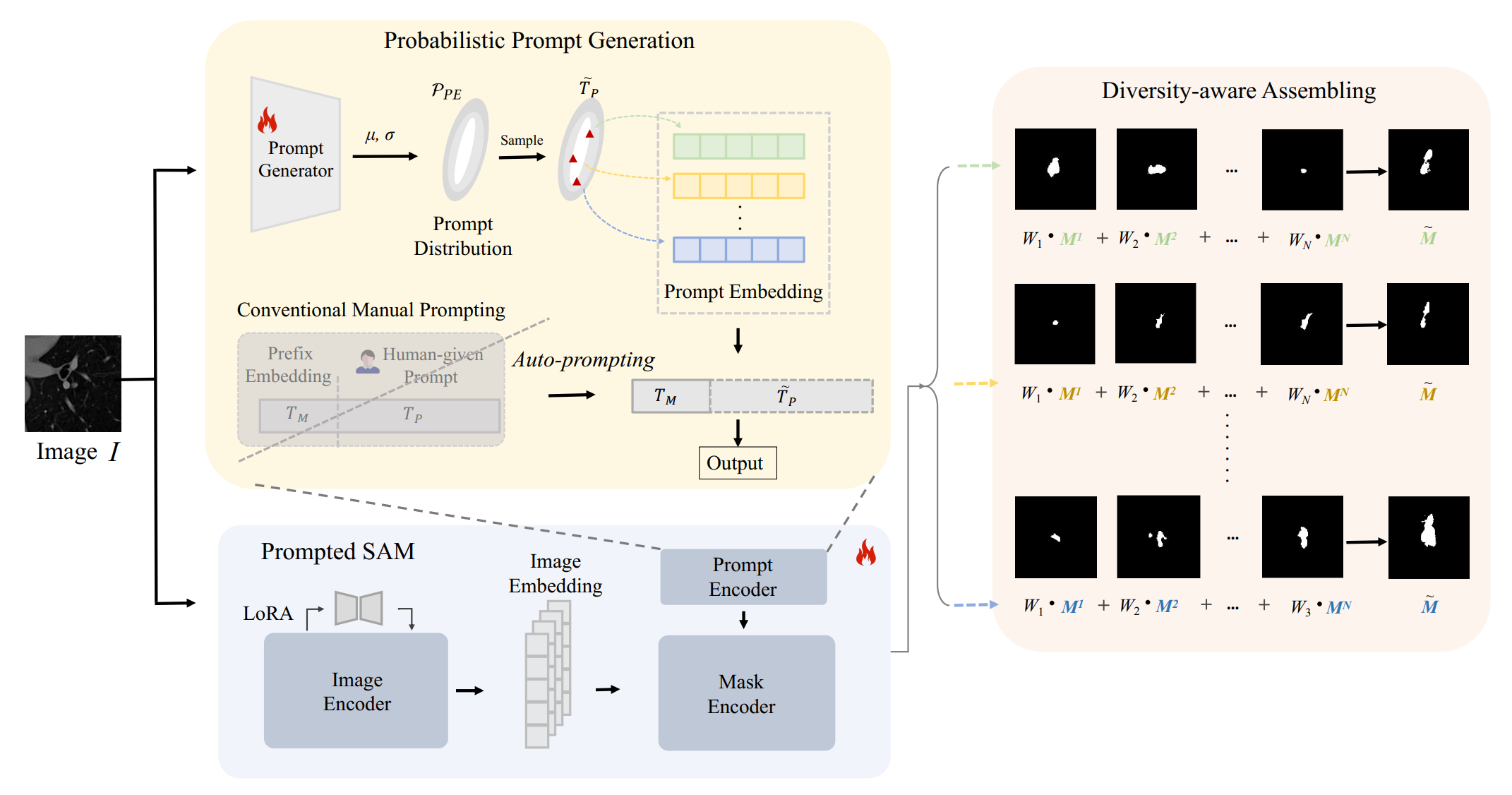
The ability to generate an array of plausible outputs for a single input has profound implications for dealing with inherent ambiguity in visual scenarios. This is evident in scenarios where diverse semantic segmentation annotations for a single medical image are provided by various experts. Existing methods hinge on probabilistic modelling of representations to depict this ambiguity and rely on extensive multi-output annotated data to learn this probabilistic space. However, these methods often falter when only a limited amount of ambiguously labelled data is available, which is a common occurrence in real-world applications. To surmount these challenges, we propose a novel framework, termed as (P²SAM), that leverages the prior knowledge of the Segment Anything Model (SAM) during the segmentation of ambiguous objects. Specifically, we delve into an inherent drawback of SAM in deterministic segmentation, i.e., the sensitivity of output to prompts, and ingeniously transform this into an advantage for ambiguous segmentation tasks by introducing a prior probabilistic space for prompts. Experimental results demonstrate that our strategy significantly enhances the precision and diversity of medical segmentation through the utilization of a small number of ambiguously annotated samples by doctors. Rigorous benchmarking experiments against state-of-the-art methods indicate that our method achieves superior segmentation precision and diversified outputs with fewer training data (using simply 5.5% samples, +12% Dmax). The (P²SAM) signifies a substantial step towards the practical deployment of probabilistic models in real-world scenarios with limited data. |
|
Huang Xilie University-Level Scholarship, 2025
University Level Outstanding Student Award, 2024 Meritorious Winner in the Mathematical Contest in Modeling (MCM), USA, 2024 |
|
International Conference on Machine Learning (ICML), 2025
International Conference on Learning Representations (ICLR), 2025 Conference on Neural Information Processing Systems (NeurIPS), 2025, 2024 |
|
|